

它正在点燃的,不止是技术架构的重构之火,更是一场全球产业权力的无声迁徙。...
它正在点燃的,不止是技术架构的重构之火,更是一场全球产业权力的无声迁徙。...

大数据算法和“老师傅”经验叠加,数字种田不仅让小麦产量提升,让种粮农民信心倍增,还带动烘干中心的建设,补齐粮食产后服务的短板。...

将大数据技术全方位融入乡村振兴的各个领域,绘制出一幅“数据引领、民生优先、产业升级”的帮扶蓝图。...

一家名为上海东软数据科技有限公司的新企业正式宣告成立,这一消息引起了业界的广泛关注。...

本文将结合其多年来对数据基础设施的实践与反思,深入探讨生成式 AI 时代对数据系统提出的全新挑战与潜在机遇。...

实现了档案信息的集中化、智能化管理。以下将从核心功能、应用场景、优势与挑战几个维度对玖影软件网络版综合档案管理系统进行深度剖析。...

第四届梧桐杯大数据应用创新大赛共吸引海内外735所高校的2338支团队报名参赛。...

当前大数据融合应用在数智、数实融合中至关重要,中国联通积极响应国家政策,从四个维度发力取得了一定成效。...

摩尔线程发布配套性能分析工具Moore Perf System的最新版本v1.3.0。...

该解决方案与其现有的 HPA 解决方案协同工作,从单一平台简化资源优化,从而提高效率和节省成本。...

HBase 数据表介绍 HBase 数据库是一个基于分布式的、面向列的、主要用于非结构化数据存储用途的开源数据库。其设计思路来源于 Google 的非开源数据库”BigTable”。 HDFS 为 HBase 提供底层存储支持,MapReduce 为其提供计算能力,ZooKeeper 为其提供协调服...
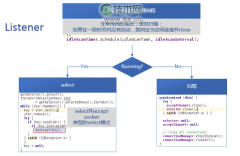
一、Listener Listener线程,当Server处于运行状态时,其负责监听来自客户端的连接,并使用Select模式处理Accept事件。 同时,它开启了一个空闲连接(Idle Connection)处理例程,如果有过期的空闲连接,就关闭。这个例程通过一个计时器来实现。 当select操...
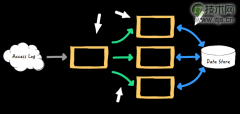
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独...
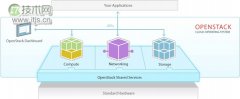
历史与愿景 OpenStackTM是一个开源的基础设施即服务(IaaS)平台。OpenStack是由Rackspace和NASA共同努力发起的,其创立于2010年。它是用来管理大量的计算机、存储以及数据中心内的网络资源,所有的管理通过一个集中式的仪表板。 OpenStack是世界上开源社区...
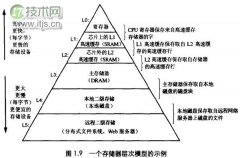
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x 进化到目前的2.6版本。我把2012年后定义成后Hadoop平台时代,这不是说不用Hadoop,而是像NoSQL (Not Only SQL)那样,有其他的选型补充。我在知...

在这篇文章中,我将介绍一下Spark SQL对Json的支持,这个特性是Databricks的开发者们的努力结果,它的目的就是在Spark中使得查询和创建JSON数据变得非常地简单。随着WEB和手机应用的流行,JSON格式的数据已经是WEB Service API之间通信以及数据的长期保存的事...
Packet是一家成立不久的公司,他们主要是为用户提供基于裸机服务器的IaaS,这篇文章的作者是Packet平台的VP,作者在文中讲述了他们构建Packet平台的动机以及在构建过程中遇到了哪些问题。他们通过借鉴OpenStack已有的服务,如Neutron、Ironic,将OpenStack对...

OpenStack为用户带来了多个好处,所以不难理解用免费的开源工具自行构建云这个概念为何吸引众多公司企业。然而,谁要是想启动OpenStack项目,就应切合实际。我们Mirantis公司在构建并部署OpenStack云环境方面有着多年的经验,见过许多痴心妄想――这会导致不...

做项目的时候遇到一个问题,在Mapper和Reducer方法中处理目标数据时,先要去检索和匹配一个已存在的标签库,再对所处理的字段打标签。因为标签库不是很大,没必要用HBase。我的实现方法是把标签库存储成HDFS上的文件,用分布式缓存存储,这样让每个slave都能...
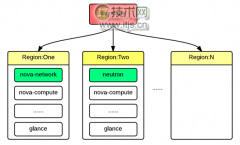
这篇文章为您介绍了网易公司基于 OpenStack 开发的一套云计算管理平台,以及在开发、运营、维护过程中遇到的问题和经验分享。网易作为大型互联网公司,IT 基础架构需要支撑包括生产、开发、测试、管理等多方面的需要,而且需求和请求的变化几乎每天都存在,这...