
AdaBoost(自适应boosting,adaptive boosting)算法
算法优缺点:
优点:泛化错误率低,易编码,可用在绝大部分分类器上,无参数调整 缺点:对离群点敏感 适用数据类型:数值型和标称型元算法(meta algorithm)
在分类问题中,我们可能不会只想用一个分类器,我们会考虑将分类器组合起来使用,这种方法称为集成方法(ensemble method)或元算法。元算法有多种形式,既可以是不同算法集成也可以是一种算法不同设置的集成。
两种集成方式(bagging & boosting)
bagging方法也称自举汇聚法(Bootstrap aggregating)。思路相当于是从数据集中随机抽样得到新的数据集,然后用新的数据集进行训练,最后的结果是新的数据集形成的分类器中的最多的类别。如从1000个样本组成的数据集中进行有放回的抽样5000次,得到5个新的训练集,将算法分别用到这五个训练集上从而得到五个分类器。 boosting则是一种通过串行训练得到结果的方法,在bagging中每个分类器的权重一样,而boosting中分类器的权重则与上一轮的成功度有关。AdaBoost
是一种用的最多的boosting,想法就是下一次的迭代中,将上一次成功的样本的权重降低,失败的权重升高。权重变化方式:
alpha(分类器权重)的变化: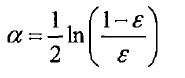 数据权重变化:
数据权重变化:
 正确分类的话:
正确分类的话:
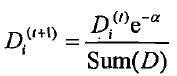 错误分类的话
错误分类的话
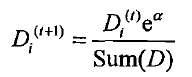
实现思路:
AdaBoost算法实现的是将弱分类器提升成为强分类器,所以这里我们首先要有一个弱分类器,代码中使用的是单层决策树,这也是使用的最多的弱分类器,然后我们就可以根据弱分类器构造出强分类器
函数:
stumpClassify(dataMatrix,dimen,threshVal,threshIneq)
单层决策树的分类器,根据输入的值与阀值进行比较得到输出结果,因为是单层决策树,所以只能比较数据一个dimen的值
buildStump(dataArr,classLabels,D)
构造单层决策树,这部分的构造的思路和前面的决策树是一样的,只是这里的评价体系不是熵而是加权的错误率,这里的加权是通过数据的权重D来实现的,每一次build权重都会因上一次分类结果不同而不同。返回的单层决策树的相关信息存在字典结构中方便接下来的使用
adaBoostTrainDS(dataArr,classLabels,numIt=40)
AdaBoost的训练函数,用来将一堆的单层决策树组合起来形成结果。通过不断调整alpha和D来使得错误率不断趋近0,甚至最终达到0
adaClassify(datToClass,classifierArr)
分类函数,datToClass是要分类的数据,根据生成的一堆单层决策树的分类结果,加权得到最终结果。
#coding=utf-8
from numpy import *
def loadSimpleData():
dataMat = matrix([[1. , 2.1],
[2. , 1.1],
[1.3 , 1.],
[1. , 1.],
[2. , 1.]])
classLabels = [1.0,1.0,-1.0,-1.0,1.0]
return dataMat, classLabels
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArry = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArry[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArry[dataMatrix[:,dimen] > threshVal] = -1.0
return retArry
#D是权重向量
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0#在特征所有可能值上遍历
bestStump = {}#用于存储单层决策树的信息
bestClasEst = mat(zeros((m,1)))
minError = inf
for i in range(n):#遍历所有特征
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j) * stepSize)#得到阀值
#根据阀值分类
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr#不同样本的权重是不一样的
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m =shape(dataArr)[0]
D = mat(ones((m,1))/m)#初始化所有样本的权值一样
aggClassEst = mat(zeros((m,1)))#每个数据点的估计值
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
#计算alpha,max(error,1e-16)保证没有错误的时候不出现除零溢出
#alpha表示的是这个分类器的权重,错误率越低分类器权重越高
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0:
break
return weakClassArr
#dataToClass 表示要分类的点或点集
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],
classifierArr[i]['thresh'],
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
return sign(aggClassEst)
def main():
dataMat,classLabels = loadSimpleData()
D = mat(ones((5,1))/5)
classifierArr = adaBoostTrainDS(dataMat,classLabels,30)
t = adaClassify([0,0],classifierArr)
print t
if __name__ == '__main__':
main()